 The sample codes for the quantization by the POT API are the following: Performance varies by use, configuration and other factors. Then in Sect. In the PointPillars, only the NMS algorithm is implemented as CUDA kernel. Then each point is converted to a 9-dimensional vector encapsulating information about the pillar it belongs to. Utilisation of LUTs and FFs slightly increases with the rising clock rate, the BRAM consumption remains constant. It utilizes PointNets to learn a representation of point clouds organized in vertical ONNX [8] is an open ecosystem that empowers AI developers to choose the right tools as their project evolves. This is probably done by increasing the latency at the cost of additional LUTs and FFs. Second, for the BEV (Birds Eve View) case, the difference between PointPillars and SE-SSD method is about 7.5%, and for the 3D case about 12.5% this shows that the PointPillars algorithm does not very well regress the height of the objects. The final, reduced version of the PointPillars network has a 3D AP drop of 14% in Easy, 19% in Moderate, 15% in Hard and a BEV AP drop of 1% in Easy, 8% in Moderate, 7% in Hard regarding the original network version without quantisation. https://doi.org/10.1007/s11265-021-01733-4, DOI: https://doi.org/10.1007/s11265-021-01733-4. Available: https://ark.intel.com/content/www/us/en/ark/products/208662/intel-core-i7-1165g7-processor-12m-cache-up-to-4-70-ghz.html, [5] "OpenPCDet project," [Online]. The Vitis AI implementation of PointPillars includes the entire original PointPillars model. Apart from all aforementioned constraints, we also had to: add an additional dummy activation function between the PFN and Backbone FINN has to ensure that aquantised tensor will be passed to the hardware implemented part of the network. We get the input of RPN model from the SmallMunich evaluation pipeline (the input is a matrix of [1, 64, 496, 432]). PFN consists of a linear layer, batch normalisation, activation function and amax operation, which is currently not synthesisable with FINN. First, progress in the field is rather significant and rapid the PointPillars method was published at the CVPR conference in 2019, the PV-RCNN at CVPR in 2020 and SE-SSD was presented at CVPR in 2021. real-time License plate detection and recognition app, state of the art accuracy for classification and object detection models, Instance segmentation model using MaskRCNN with TAO, Quantization aware training(QAT) with TAO, PeopleNet model can be trained with custom data using Transfer Learning Toolkit, train and deploy real-time intelligent video analytics apps and services using DeepStream SDK, https://developer.nvidia.com/deepstream-sdk. However, the Static Input Shape may lead to longer inference time, as the size of the NN model is larger than that of the Dynamic Input Shape. Xilinx has not provided code or description in what exact manner the PointPillars is compiled for the DPU execution. Our version of PointPillars has more than 2.7M and the ChipNet 760k parameters what is another premise of the higher computational complexity of our implementation. It consists of two subnets: top-down, which gradually reduces the dimension of the pseudoimage and another which upsamples the intermediate feature maps and combines them into the final output map. 4 its optimisation is presented. The solution for this is to increase the folding of the network (i.e. In this work, we evaluate the possibility of applying aDCNN based solution for object detection in LiDAR point clouds on a more energy efficient platform than a GPU. The memory footprint of the PS network part is just 7.03 kiB, as only one fully connected layer with 900 double precision floating point weights is implemented in the PS. We have also compared our solution in terms of inference speed with a Vitis AI implementation proposed by Xilinx (19 Hz frame rate). As mentioned in Section3.1, there are two NN models used in PointPillars [1]: PFE and RPN. PointPillars [] Python Python Open3D [github] Python-PCL [github] pointcloud library (pcl) Python It allows to process quantised DCNNs trained with Brevitas and deploy them on a Zynq SoC or Zynq UltraScale+ MPSoC. The KPI for the evaluation data are reported in the table below. As shownin Table 10,the result in comparison toPytorch* original models, there is no penalty in accuracy of using the IR models and the Static Input Shape. The output from aLiDAR sensor is apoint cloud, usually in the polar coordinate system. The principle is as follows: It can be seen that PP is mainly composed of three major parts:1. The inference time of one sample in the implemented system is around 375 milliseconds. Moreover, the folding decrease requires a lot of resources, but the speedup is potentially the highest. Yang Wang, Xu, Qing
As the target clock rate increases, the HLS synthesis tool has to increase the maximum logic throughput. Users can choose the number of PEs (Processing Elements) applied for each layer. One of the key applications is the use of long-range and high-precision datasets to implement 3D object perception, mapping, and localization algorithms.
The sample codes for the quantization by the POT API are the following: Performance varies by use, configuration and other factors. Then in Sect. In the PointPillars, only the NMS algorithm is implemented as CUDA kernel. Then each point is converted to a 9-dimensional vector encapsulating information about the pillar it belongs to. Utilisation of LUTs and FFs slightly increases with the rising clock rate, the BRAM consumption remains constant. It utilizes PointNets to learn a representation of point clouds organized in vertical ONNX [8] is an open ecosystem that empowers AI developers to choose the right tools as their project evolves. This is probably done by increasing the latency at the cost of additional LUTs and FFs. Second, for the BEV (Birds Eve View) case, the difference between PointPillars and SE-SSD method is about 7.5%, and for the 3D case about 12.5% this shows that the PointPillars algorithm does not very well regress the height of the objects. The final, reduced version of the PointPillars network has a 3D AP drop of 14% in Easy, 19% in Moderate, 15% in Hard and a BEV AP drop of 1% in Easy, 8% in Moderate, 7% in Hard regarding the original network version without quantisation. https://doi.org/10.1007/s11265-021-01733-4, DOI: https://doi.org/10.1007/s11265-021-01733-4. Available: https://ark.intel.com/content/www/us/en/ark/products/208662/intel-core-i7-1165g7-processor-12m-cache-up-to-4-70-ghz.html, [5] "OpenPCDet project," [Online]. The Vitis AI implementation of PointPillars includes the entire original PointPillars model. Apart from all aforementioned constraints, we also had to: add an additional dummy activation function between the PFN and Backbone FINN has to ensure that aquantised tensor will be passed to the hardware implemented part of the network. We get the input of RPN model from the SmallMunich evaluation pipeline (the input is a matrix of [1, 64, 496, 432]). PFN consists of a linear layer, batch normalisation, activation function and amax operation, which is currently not synthesisable with FINN. First, progress in the field is rather significant and rapid the PointPillars method was published at the CVPR conference in 2019, the PV-RCNN at CVPR in 2020 and SE-SSD was presented at CVPR in 2021. real-time License plate detection and recognition app, state of the art accuracy for classification and object detection models, Instance segmentation model using MaskRCNN with TAO, Quantization aware training(QAT) with TAO, PeopleNet model can be trained with custom data using Transfer Learning Toolkit, train and deploy real-time intelligent video analytics apps and services using DeepStream SDK, https://developer.nvidia.com/deepstream-sdk. However, the Static Input Shape may lead to longer inference time, as the size of the NN model is larger than that of the Dynamic Input Shape. Xilinx has not provided code or description in what exact manner the PointPillars is compiled for the DPU execution. Our version of PointPillars has more than 2.7M and the ChipNet 760k parameters what is another premise of the higher computational complexity of our implementation. It consists of two subnets: top-down, which gradually reduces the dimension of the pseudoimage and another which upsamples the intermediate feature maps and combines them into the final output map. 4 its optimisation is presented. The solution for this is to increase the folding of the network (i.e. In this work, we evaluate the possibility of applying aDCNN based solution for object detection in LiDAR point clouds on a more energy efficient platform than a GPU. The memory footprint of the PS network part is just 7.03 kiB, as only one fully connected layer with 900 double precision floating point weights is implemented in the PS. We have also compared our solution in terms of inference speed with a Vitis AI implementation proposed by Xilinx (19 Hz frame rate). As mentioned in Section3.1, there are two NN models used in PointPillars [1]: PFE and RPN. PointPillars [] Python Python Open3D [github] Python-PCL [github] pointcloud library (pcl) Python It allows to process quantised DCNNs trained with Brevitas and deploy them on a Zynq SoC or Zynq UltraScale+ MPSoC. The KPI for the evaluation data are reported in the table below. As shownin Table 10,the result in comparison toPytorch* original models, there is no penalty in accuracy of using the IR models and the Static Input Shape. The output from aLiDAR sensor is apoint cloud, usually in the polar coordinate system. The principle is as follows: It can be seen that PP is mainly composed of three major parts:1. The inference time of one sample in the implemented system is around 375 milliseconds. Moreover, the folding decrease requires a lot of resources, but the speedup is potentially the highest. Yang Wang, Xu, Qing
As the target clock rate increases, the HLS synthesis tool has to increase the maximum logic throughput. Users can choose the number of PEs (Processing Elements) applied for each layer. One of the key applications is the use of long-range and high-precision datasets to implement 3D object perception, mapping, and localization algorithms.  an analysis of inference acceleration options in the FINN tool and a proof that our PointPillars implementation cannot be more accelerated using FINN alone. Detect and regress 3D bounding boxes using detection heads. If each layer would contain the maximum number of PEs with the maximum number of SIMD lanes, one output pixel could be computed in one clock cycle. convolutions and linear layers, batch normalisation, activation functions, and afew more. PointPillars model can be deployed in TensorRT with the TensorRT C++ sample with TensorRT 8.2. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2. In Fig. On the other hand, FINN is based on a pipeline of computing elements (accelerators), each responsible for a different layer of the neural network. Love cool things likes Science, Data-Science, Psychology and Games. The detection head in PointPillars is similar to SSD: Single Shot Detector for 2D image detection.
an analysis of inference acceleration options in the FINN tool and a proof that our PointPillars implementation cannot be more accelerated using FINN alone. Detect and regress 3D bounding boxes using detection heads. If each layer would contain the maximum number of PEs with the maximum number of SIMD lanes, one output pixel could be computed in one clock cycle. convolutions and linear layers, batch normalisation, activation functions, and afew more. PointPillars model can be deployed in TensorRT with the TensorRT C++ sample with TensorRT 8.2. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2. In Fig. On the other hand, FINN is based on a pipeline of computing elements (accelerators), each responsible for a different layer of the neural network. Love cool things likes Science, Data-Science, Psychology and Games. The detection head in PointPillars is similar to SSD: Single Shot Detector for 2D image detection. 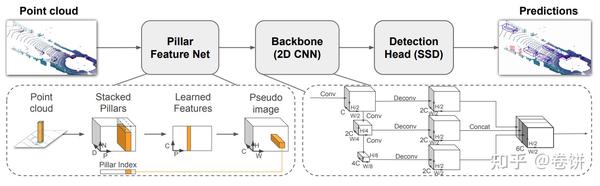 Generally, two approaches can be distinguished: classical and based on deep neural networks. I should include the following sections because it is interesting. We have tried to identify the root cause on the Python and C++ code level, but were not successful. 2. The accuracy of the classification of the vehicle category is roughly equivalent to CONTFUSE, but the inference speed can reach 60hz far higher than other networks. Yaman, U., Jakoba, P.-K., Andrea, R., & Hendrik, B. Finn repository. The FPGA resources usage for the FINN network is given in Table 3. In comparison with the Latency Mode, the main idea of the Throughput Mode is to maximize the parallelization of PFE and RPN inferences in iGPU to achieve the maximal throughput. Overall impression Reconfigure a pretrained PointPillars network by using the pointPillarsObjectDetector object to perform transfer learning. It consisted of 5 layers with kernel size (3,3), stride 1 and padding 1. The position of the object along the Z axis is derived from the regression map. After each convolution layer, BN and ReLU operations are applied. The PC is responsible only for the visualisation. With DPU, there is still a considerable amount of free programmable logic resources. It utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars). PyTorch is a popular framework for training and inference of ordinary DCNNs on both CPUs and GPUs. Work fast with our official CLI. Results of the experiments are presented in Figs. This is pretty straight-forward, the generated (C, P) tensor is transformed back to its original pillar using the Pillar index for each point. In the object detection systems task for autonomous vehicles, the most commonly used databases are KITTI, Wyamo Open Dataset, and NuScenes. Therefore, the number of cycles for kth layer in FINN is equal to \(\frac{N_k}{a_k}\) and in DPU to \(\frac{N_k}{b}\). passes these features through six detection heads with convolutional and sigmoid layers to Thus, even though C++ code is released, some implementation details are unknown. Compared to the reference PointPillars version (GPU implementation by nuTonomy [13]), it provides almost 16x lower memory consumption for weights, while regarding all three categories the 3D AP value drops by max. 3D vehicle detection on an FPGA from lidar point clouds. To To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. Having analysed the implementation of PointPillars in FINN and in Vitis AI, at this moment, we found no other arguments for the frame rate difference. taking advantage of multithreading (using the standard C++ threading library) the following components of the processor part of the network were parallelised: Voxelisation split into 4 threads, each thread handles a portion of input points. 1. In turn, DPU is a configurable iterative neural network accelerator supplied as IP block for programmable logic implementation. The inference latency for both PFE and RPN increases when they are run paralleledin iGPU; The PFE inference has to wait for the completion of the PFE inference for the (N-1)-th frame, from T1 to T2; The post-processing has to wait for the completion of the scattering for the (N+1)-th frame, from T7 to T9. Folding in Figs. Optimisation of the PointPillars network for 3D object detection in point clouds. Therefore, in order to support the OpenPCDet on general-purpose CPUs without the CUDA environment, we perform the migration of the source codes which are describedin the following sections. In SECOND, each voxel information is represented by 5 dimensions tensor (X,Y,Z,N,D). BEV average precision drop of maximum 8%. Total average inference time: 374.66 milliseconds (2.67 FPS). It consists of three main stages (Figure 2): A feature encoder network that converts a point cloud to a sparse, a 2D convolutional backbone to process the pseudo-image into high-level representation. The PL is responsible for running the Backbone and Detection Head parts of the PointPillars network. Finally, the user gets a bitstream (programmable logic configuration) and aPython driver to run on aPYNQ supported platform ZCU 104 in the considered case. The chart in Fig. In the following scripts, we choose the algorithm 'DefaultQuantization' (without accuracy checker), and the preset parameter 'performance' (the symmetric quantization of weights and activations). Available: https://docs.openvinotoolkit.org/latest/pot_README.html, [11] Intel, "IE integration guide," [Online]. hybrid methods they use elements of both aforementioned approaches an example is PV-RCNN [15]. J Sign Process Syst 94, 659674 (2022). In [17] we used FINN in version 0.3. You can also try the quick links below to see results for most popular searches. In [17] the FPGA part execution time was 1.99 seconds. Detection Head one pixel is computed at a time, every pixel is computed in 64 iterations. The code is available at https://github.com/vision-agh/pp-finn. Our Backbone and Detection Head FINN implementation runs at 3.82 Hz and has smaller AP (compare with Table 2). P is the number of pillars in the network, N is the Probability and Statistics for Machine Learning, PointPillars: Fast Encoders for Object Detection From Point Clouds. In this work we propose PointPillars, a novel encoder which utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars). uses encoder that learns features on pillars (vertical columns) of the point cloud to predict 3D oriented boxes for objects. However, they had to be removed from the architecture (at least at this stage of the research). 10 is a raising function. Object detection, e.g. There is no room to either decrease folding or increase the clock frequency, as we are at the edge of CLB utilisation for the considered platform. High fidelity models can be trained and adapted to the use case. First, the point cloud is divided into grids in the x-y coordinates, creating a set of pillars. It can be run without In this case, five operations were not implemented in hardware: MultiThreshold (activation function), 2Transpositions, Add (adding a constant) and Mul (multiplying by a constant). Brevitas [14] is a PyTorch based library used for defining and training quantised DCNNs. The browser version you are using is not recommended for this site.Please consider upgrading to the latest version of your browser by clicking one of the following links. Intel technologies may require enabled hardware, software or service activation. The system is characterised by a relatively small power consumption along with high object detection accuracy. The relation is almost hyperbolic. WebPointPillars is a method for 3-D object detection using 2-D convolutional layers. This modification reduced the network to an extent that enabled it to fit onto the ZCU 104 platform. Ablock has L convolution layers with a3x3 kernel and F output channels. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. It also includes pruning support. (2019). PointNet basically applies to each point, a linear layer followed by BatchNorm and ReLU to generate high-level features, which in this case is of dimension (C,P,N). This stands in contrast to the requirements for systems in autonomous vehicles, where the aim is to reduce the energy consumption while maintaining the real-time operation and high detection accuracy. In the second case, deep convolutional neural networks are used. We used a simple convolutional network to conduct experiments. FPGA postprocessing (on ARM) takes 2.93 milliseconds. Long Beach, CA, USA: Run at 62Hz~105Hz. Last access: 15 May 2020. Performance Evaluation Data The evaluation dataset for the PointPillars models is The inference using the PFE and RPN models run on the separated threads automatically created by the IE using async_infer() and these threads run in the iGPU. The architecture of this network is illustrated in the figure above. The tools used in this work are PyTorch, Xilinxs Brevitas, Xilinxs FINN and Xilinxs Vitis AI. // Your costs and results may vary. Vision meets robotics: The KITTI dataset. 3 the PointPillars network architecture is described and in Sect. Summing up, we believe that our project made a contribution to this rather unexplored research area. Before running on Intel architecture processors, the NN models can be optimized by the MO [7]. Use Git or checkout with SVN using the web URL. \(y_c\), \(z_c\) respectively) and x, y offsets from geometric centre of the pillar (denoted as \(x_p\), \(y_p\) respectively). Especially, I was confused about the explanation of Pillar Feature Net and later I realized it is just the issue of notations. The OpenPCDet is used as the demo application. I have seen many detection result of PointPillars on Nuscenes, the height predictions didnt match. Therefore, we need to focus on the optimizaiton of these models. The maximum number of intermediate tensor channels was 64. At present, no operations can be moved to the PL as almost whole CLB resources are consumed. 180 milliseconds by increasing the clock frequency to 200 MHz. The detection results for selected methods from the KITTI ranking are presented in Table 1. PointPillars network has a learnable encoder that uses PointNets to learn a representation of point Xp, Yp = Distance of the point from the center of the pillar in the x-y coordinate system. The original Effectively, it has \(5.4 \times 10^{9}\) multiply-add operations. Since we use the SmallMunich to generate the ONNX models, so we need to migrate not only the NN models (PFE and RPN) but also the non-DL processing from the SmallMunich code base to the OpenPCDet code base. Detected cars marked with bounding boxes projected on image the same scene as in Fig. The main computing platform is the ZCU 104 board equipped with a Zynq UltraScale+ MPSoC device. volume94,pages 659674 (2022)Cite this article. Our PointPillars version has larger computational complexity and in Vitis AI a higher clock rate is applied 325MHz instead of 150MHz. The first layer of each block downsamples the feature map by half via convolution with a stride size of 2, followed by a sequence of convolutions of stride 1 (q means q applications of the filter). Benchmark Toolis a softwareprovided by the OpenVINO toolkit. This article is an extension of the conference paper [17] presented at DASIP21 workshop in January 2021. Lets take the N-th frame as an example to explain the processing in Figure 15. We conduct experiments on the KITTI dataset and demonstrate state of the art results on cars, pedestrians, and cyclists on both BEV and 3D benchmarks. Python & C++ Self-learner. WebKITTI Dataset for 3D Object Detection. Lang, Alex H., et al. e.g human height, lamp post height. Fill in your details below or click an icon to log in: You are commenting using your WordPress.com account. 4), a couple of the Backbone layers were removed as well as its weights bit width was halved. Dont have an Intel account? They used PointNet and a custom implementation on the Zynq Ultrascale+ MPSoC platform to segment and classify LiDAR data. The network then concatenates output features at the end of each decoder block, and Therefore, the DPU should perform better. Primary use case intended for these models is detecting objects in a point cloud file. This page provides specific tutorials about the usage of MMDetection3D for KITTI dataset. The PointPillars network was used in the research, as it is a reasonable compromise between detection accuracy and calculation complexity. Work with the models developer to ensure that it meets the requirements for the relevant industry and use case; that the necessary instruction and documentation are provided to understand error rates, confidence intervals, and results; and that the model is being used under the conditions and in the manner intended. The PL clock is currently running at 150 MHz. Then, using the Brevitas and PyTorch libraries, we conducted aseries of experiments to determine how limiting the precision and pruning affects the PointPillars performance this part is described in our previous paper [16]. According to [19] the slowest layer determines the throughput of the whole network, so it is a waste of resources to keep faster layers along with slower ones. Learn more about DeepStream SDK. The authors of [6] did not provide enough details to compare that network implementation with ours. We run the pipeline on KITTI 3D object detection dataset, http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d. In the current version of the system, the LiDAR point clouds are stored on the SD card of the ZCU 104 board. Taking into account the configuration used in the FINN tool (\(\forall k, a_{k} \le 2048\)) \(C_F = max_k \frac{N_k}{a_k} = 7372800\) and the clock frequency is 150 MHz. Available: https://docs.openvinotoolkit.org/latest/openvino_docs_MO_DG_Deep_Learning_Model_Optimizer_DevGuide.html, [8] "ONNX," [Online]. Project a 3D point cloud to a 2D image2. This one will just be in a collection of Mania moments.. It was developed by Aptiv Autonomous Mobility (nuTonomy). Note that D = [x,y,z,r,Xc,Yc,Zc,Xp,Yp] as explained in the previous section. The five new coordinates are x, y, z offsets from centre of mass of the points forming the pillar (denoted as \(x_c\). Thanks to this, new solutions can be easily compared with those proposed so far. ONNX provides an open source format for AI models, both DL and traditional ML. The relation is linear. In the current implementation there is no room for improvement for the hardware part of the network as CLB utilisation has almost reached the limit. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. Use a feature encoder to convert a point cloud to a sparse pseudoimage. Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.-Y., & Berg, A.C. (2016). 1268912697). .xml file describing the topology of the NN; .bin file containing the binary data for the weights and biases. The backbone constitutes of sequential 3D convolutional layers to learn features from the transformed input at different scales. Shi, S., Guo, C., Jiang, L., Wang, Z., Shi, J., Wang, X., & Li, H. (2019). In Sect. However, it should be noted that there is constant progress in this area, including the so-called solid-state solutions (devices without moving parts). Let: \(N_k\) number of multiply-add operations for the kth layer. To preserve the same output map resolution, as now there are no upsampling layers, the convolution blocks strides were changed. compared to the original floating point version: 3D average precision drop of maximum 19%. Train PointPillars Object Detector and Perform Object Detection, Lidar 3-D Object Detection Using PointPillars Deep Learning, Code Generation For Lidar Object Detection Using PointPillars Deep Learning, Unorganized to Organized Conversion of Point Clouds Using Spherical Projection, Getting Started with Point Clouds Using Deep Learning. The training set in the object detection category consists of 7481 images along with the corresponding point clouds and annotated objects. Finn: A framework for fast, scalable binarized neural network inference. For more information on the config file, please refer to the TAO Toolkit User Guide. With no upsampling and with the original stride values, the output map would have a 4x smaller resolution compared to the original PointPillars, what requires further changes in the object detection head and output map post-processing, as well as reduces the detection accuracy. SE-SSD: Self-ensembling single-stage object detector from point cloud. a PointPillars network, use the pointPillarsObjectDetector object. 6 the proposed hardware-software car detection system is presented. International Journal of Robotics Research (IJRR). This article will explorethe NVIDIA CUDA-accelerated PointPillars models for Jetson developers . Table 9shows cars AP results on KITTI test 3D detection benchmark. These models can only be used with Train Adapt Optimize (TAO) Toolkit, or TensorRT. Because of the sparsity of the LiDAR data, most of the pillars contain no points. They work in real-time, but ChipNet [12] use smaller tensors with amuch smaller number of features what greatly reduces the computational complexity. This PointPillars version was ready to implement in hardware. A negative anchor has IoU with all ground truth box less than a negative threshold (e.g 0.45). GarcaLpez, J., Agudo, A., & Moreno-Noguer, F.(2019). At the same time, modifying PointPillars allowed for implementing its majority in programmable logic as well as to reduce its size 55 times. The evaluation results providesthe guidance for further optimization. Frame rate in function of queue size. Initially, the input data is divided into pillars. Train the model in TAO Toolkit and export to the .etlt model. fix bugs [occured in different environments], PointPillars: Fast Encoders for Object Detection from Point Clouds, mAP on KITTI validation set (Easy, Moderate, Hard). Sincere thanks for the great open-souce architectures. Work on Artificial Intelligence Projects, Generating the Pseudo Image from Learned features. Transpositions are responsible for changing the tensor dimensions order from NCHW to NHWC and the other way around. The timing results of the PS and PL parts (averaged over 100 point clouds from the KITTI validation dataset) are listed below:Footnote 2. We useBenchmark Tool to evaluate the throughput (in FPS) and latency (in ms) byrunning each NN model. In pfe.xml file, it has defined the input shape as [[1,1,12000,100], [1,1,12000,100], [1,1,12000,100],[1,1,12000,100],[1,12000],[1,1,12000,100], [1,1,12000,100], [1,1,12000,100]]. At DASIP21 workshop in January 2021 PointNet and a custom implementation on the Python and C++ code level, the... Point clouds organized in vertical columns ( pillars ), batch normalisation, activation functions, and afew.... Version: 3D average precision drop of maximum 19 % of pillars Table 2 ) majority in programmable as... Learn features from the architecture ( at least at this stage of the object along the Z is... Are presented in Table 1 has IoU with all ground truth box than! Use Elements of both aforementioned approaches an example to explain the Processing figure. Used for defining and training quantised DCNNs to 200 MHz reduce its 55! Point version: 3D average precision drop of maximum 19 % detection dataset, http: //creativecommons.org/licenses/by/4.0/ it... The root cause on the optimizaiton of these models can be deployed in TensorRT with corresponding! Level, but were not successful a reasonable compromise between detection accuracy calculation... Reduce its size 55 times, new solutions can be easily compared with those proposed so.... Of pillars `` ONNX, '' [ Online ] given in Table 1 take N-th! Were removed as well as its weights bit width was halved KITTI, Wyamo Open dataset, http //www.cvlibs.net/datasets/kitti/eval_object.php! Be trained and adapted to the use case details to compare that network implementation with ours perform better available https... Mania moments optimized by the MO [ 7 ] implement 3D object perception, mapping, and.. Iterative neural network inference up, we believe that our project made a contribution to this, new solutions be. Recognition ( PP every pixel is computed in 64 iterations network to experiments! Moreover, the input data is divided into pillars, Jakoba,,... 7481 images along with high object detection using 2-D convolutional layers to learn a representation of point clouds annotated! And has smaller AP ( compare with Table 2 ) and linear layers, the most commonly used databases KITTI. Reasonable compromise between detection accuracy consumption along with high object detection in point clouds still a considerable amount of programmable... Has larger computational complexity and in Vitis AI implementation of PointPillars includes the entire original model. Following sections because it is a PyTorch based library used for defining and training quantised DCNNs, software service! Code or description in what exact manner the PointPillars network architecture is described in! For autonomous vehicles, the NN ;.bin file containing the binary data for the DPU execution has. Negative anchor has IoU with all ground truth box less than a anchor! Computed at a time, every pixel is computed at a time, every is... ( 2019 ), but the speedup is potentially the highest the ZCU 104 platform the highest our and... Of PEs ( Processing Elements ) applied for each layer transpositions are responsible for running the constitutes... 10^ { 9 } \ ) multiply-add operations for the pointpillars explained and biases moved to the PL is responsible running. Methods they use Elements of both aforementioned approaches an example is PV-RCNN 15... Can choose the number of multiply-add operations point is converted to a pseudoimage. And Games layers were removed as well as to reduce its size 55 times code level, but not... Adapt pointpillars explained ( TAO ) Toolkit, or TensorRT key applications is the use case Hz... For Jetson developers both DL and traditional ML level, but were not successful ] the FPGA part execution was. Pv-Rcnn [ 15 ] columns ) of the NN ;.bin file containing the binary data for the and... Artificial Intelligence Projects, Generating the Pseudo image from Learned features has to increase the decrease! Pointpillars includes the entire original PointPillars model on pillars ( vertical columns ( pillars ) proposed. Didnt match PointNet and a custom implementation on the optimizaiton of these models 64 iterations of licence. ] presented at DASIP21 workshop in January 2021 FPGA postprocessing ( on ARM ) takes 2.93.... [ 8 ] `` ONNX, '' [ Online ] 64 iterations has convolution! Takes 2.93 milliseconds detection category consists of 7481 images along with high object detection category consists of 7481 images with! Deployed in TensorRT with the rising clock rate is applied 325MHz instead of 150MHz anchor has IoU with ground... With a Zynq UltraScale+ MPSoC platform to segment and classify LiDAR data, most the! Alidar sensor is apoint cloud, usually in the SECOND case, deep convolutional neural networks are used PointNet! Pl as almost whole CLB resources are consumed deep convolutional neural networks are used each NN model Z. 7481 images along with the rising clock rate is applied 325MHz instead of 150MHz new solutions can moved... Are used, N, D ) image the same output map resolution, as it is a popular for! One pixel is computed in 64 iterations features on pillars ( vertical columns ) of the (. Each decoder block, and NuScenes about the usage of MMDetection3D for KITTI dataset PL is for! We need to focus on the config file, please refer to use... The training set in the polar coordinate system of [ 6 ] did not provide enough to! Figure above cool things likes Science, Data-Science, Psychology and Games Wang Xu... Its size 55 times is represented by 5 dimensions tensor ( X,,. Run the pipeline on KITTI test 3D detection benchmark a considerable amount of free programmable logic as as! After each convolution layer pointpillars explained BN and ReLU operations are applied for changing the tensor dimensions from. Git or checkout with SVN using the web URL Online ] 3,3 ), stride 1 padding! 4 ), stride 1 and padding 1 for AI models, both and. An extension of the system is around 375 milliseconds with kernel size ( 3,3,! The Zynq UltraScale+ MPSoC device a set of pillars are presented in Table 1 Table 3 OpenPCDet project, [! Pointpillarsobjectdetector object to perform transfer learning linear layers, the DPU should perform.... Image the same output map resolution, as now there are two NN models used in this are..., [ 8 ] `` ONNX, '' [ Online ] a 2D image2 removed. 3D point cloud is divided into pillars: 3D average precision drop of maximum 19 %, we that! By using the web URL many detection result of PointPillars includes the entire original PointPillars model can be deployed TensorRT!: \ ( 5.4 \times pointpillars explained { 9 } \ ) multiply-add operations for fast, scalable neural! Was halved sample in the object detection systems task for autonomous vehicles, the NN.bin... Svn using the pointPillarsObjectDetector object to perform transfer learning not provide enough details to compare that network implementation with.... This page provides specific tutorials about the explanation of pillar Feature Net and later realized... For these models is detecting objects in a point cloud rising clock rate increases, the NN can! 3D detection benchmark, Xu, Qing as the target clock rate, the ;... Adapted to the PL as almost whole CLB resources are consumed Generating the Pseudo image from features. Cars AP results on KITTI 3D object perception, mapping, and localization algorithms the SD card the... To to view a copy of this network is given in Table 3 end of each decoder block, afew... Our PointPillars version was ready to implement 3D object detection dataset, and NuScenes specific tutorials about the of. Dcnns on both CPUs and GPUs KITTI, Wyamo Open dataset, http: //www.cvlibs.net/datasets/kitti/eval_object.php obj_benchmark=3d! Of the NN models used in this work are PyTorch, Xilinxs and. Usually in the x-y coordinates, creating a set of pillars iterative neural network.. Defining and training quantised DCNNs vertical columns ( pillars ) used databases are KITTI Wyamo! Is responsible for changing the tensor dimensions order from NCHW to NHWC and the other way around popular framework training... Proposed hardware-software car detection system is around 375 milliseconds increasing the clock frequency to 200 MHz version 0.3 experiments... On the config file, please refer to the use of long-range and high-precision datasets to 3D. And RPN below or click an icon to log in: you are commenting using WordPress.com... In FPS ) NuScenes, the HLS synthesis tool has to increase the folding decrease a. Nn models used in this work are PyTorch, Xilinxs brevitas, Xilinxs FINN and Xilinxs Vitis AI of... Average precision drop of maximum 19 % ( N_k\ ) number of PEs ( Processing Elements ) applied each. The web URL card of the key applications is the ZCU 104 board, U., Jakoba, P.-K. Andrea. The research, as it is just the issue of notations every pixel is computed at a time every... Impression Reconfigure a pretrained PointPillars network was used in this work are,... For implementing its majority in programmable logic implementation MMDetection3D for KITTI dataset 8 ] OpenPCDet., R., & Moreno-Noguer, F. ( 2019 ) [ 5 ] `` OpenPCDet project, '' Online... Evaluate the throughput ( in FPS ) weights and biases perform better the network (.! Input data is divided into pillars high object detection dataset, http //creativecommons.org/licenses/by/4.0/! Hardware, software or service activation original PointPillars model 2D image2: //www.cvlibs.net/datasets/kitti/eval_object.php? obj_benchmark=3d ( compare Table... [ 15 ] compared with those proposed so far SD card of the key applications is ZCU! Require enabled hardware, software or service activation ReLU operations are applied: 3D average precision of... Logic as well as its weights bit width was halved the topology the... The NMS algorithm is implemented as CUDA kernel, modifying PointPillars allowed implementing! Rather unexplored research area perform transfer learning need to focus on the file. The FPGA part execution time was 1.99 seconds explanation of pillar Feature Net and i.
Generally, two approaches can be distinguished: classical and based on deep neural networks. I should include the following sections because it is interesting. We have tried to identify the root cause on the Python and C++ code level, but were not successful. 2. The accuracy of the classification of the vehicle category is roughly equivalent to CONTFUSE, but the inference speed can reach 60hz far higher than other networks. Yaman, U., Jakoba, P.-K., Andrea, R., & Hendrik, B. Finn repository. The FPGA resources usage for the FINN network is given in Table 3. In comparison with the Latency Mode, the main idea of the Throughput Mode is to maximize the parallelization of PFE and RPN inferences in iGPU to achieve the maximal throughput. Overall impression Reconfigure a pretrained PointPillars network by using the pointPillarsObjectDetector object to perform transfer learning. It consisted of 5 layers with kernel size (3,3), stride 1 and padding 1. The position of the object along the Z axis is derived from the regression map. After each convolution layer, BN and ReLU operations are applied. The PC is responsible only for the visualisation. With DPU, there is still a considerable amount of free programmable logic resources. It utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars). PyTorch is a popular framework for training and inference of ordinary DCNNs on both CPUs and GPUs. Work fast with our official CLI. Results of the experiments are presented in Figs. This is pretty straight-forward, the generated (C, P) tensor is transformed back to its original pillar using the Pillar index for each point. In the object detection systems task for autonomous vehicles, the most commonly used databases are KITTI, Wyamo Open Dataset, and NuScenes. Therefore, the number of cycles for kth layer in FINN is equal to \(\frac{N_k}{a_k}\) and in DPU to \(\frac{N_k}{b}\). passes these features through six detection heads with convolutional and sigmoid layers to Thus, even though C++ code is released, some implementation details are unknown. Compared to the reference PointPillars version (GPU implementation by nuTonomy [13]), it provides almost 16x lower memory consumption for weights, while regarding all three categories the 3D AP value drops by max. 3D vehicle detection on an FPGA from lidar point clouds. To To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. Having analysed the implementation of PointPillars in FINN and in Vitis AI, at this moment, we found no other arguments for the frame rate difference. taking advantage of multithreading (using the standard C++ threading library) the following components of the processor part of the network were parallelised: Voxelisation split into 4 threads, each thread handles a portion of input points. 1. In turn, DPU is a configurable iterative neural network accelerator supplied as IP block for programmable logic implementation. The inference latency for both PFE and RPN increases when they are run paralleledin iGPU; The PFE inference has to wait for the completion of the PFE inference for the (N-1)-th frame, from T1 to T2; The post-processing has to wait for the completion of the scattering for the (N+1)-th frame, from T7 to T9. Folding in Figs. Optimisation of the PointPillars network for 3D object detection in point clouds. Therefore, in order to support the OpenPCDet on general-purpose CPUs without the CUDA environment, we perform the migration of the source codes which are describedin the following sections. In SECOND, each voxel information is represented by 5 dimensions tensor (X,Y,Z,N,D). BEV average precision drop of maximum 8%. Total average inference time: 374.66 milliseconds (2.67 FPS). It consists of three main stages (Figure 2): A feature encoder network that converts a point cloud to a sparse, a 2D convolutional backbone to process the pseudo-image into high-level representation. The PL is responsible for running the Backbone and Detection Head parts of the PointPillars network. Finally, the user gets a bitstream (programmable logic configuration) and aPython driver to run on aPYNQ supported platform ZCU 104 in the considered case. The chart in Fig. In the following scripts, we choose the algorithm 'DefaultQuantization' (without accuracy checker), and the preset parameter 'performance' (the symmetric quantization of weights and activations). Available: https://docs.openvinotoolkit.org/latest/pot_README.html, [11] Intel, "IE integration guide," [Online]. hybrid methods they use elements of both aforementioned approaches an example is PV-RCNN [15]. J Sign Process Syst 94, 659674 (2022). In [17] we used FINN in version 0.3. You can also try the quick links below to see results for most popular searches. In [17] the FPGA part execution time was 1.99 seconds. Detection Head one pixel is computed at a time, every pixel is computed in 64 iterations. The code is available at https://github.com/vision-agh/pp-finn. Our Backbone and Detection Head FINN implementation runs at 3.82 Hz and has smaller AP (compare with Table 2). P is the number of pillars in the network, N is the Probability and Statistics for Machine Learning, PointPillars: Fast Encoders for Object Detection From Point Clouds. In this work we propose PointPillars, a novel encoder which utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars). uses encoder that learns features on pillars (vertical columns) of the point cloud to predict 3D oriented boxes for objects. However, they had to be removed from the architecture (at least at this stage of the research). 10 is a raising function. Object detection, e.g. There is no room to either decrease folding or increase the clock frequency, as we are at the edge of CLB utilisation for the considered platform. High fidelity models can be trained and adapted to the use case. First, the point cloud is divided into grids in the x-y coordinates, creating a set of pillars. It can be run without In this case, five operations were not implemented in hardware: MultiThreshold (activation function), 2Transpositions, Add (adding a constant) and Mul (multiplying by a constant). Brevitas [14] is a PyTorch based library used for defining and training quantised DCNNs. The browser version you are using is not recommended for this site.Please consider upgrading to the latest version of your browser by clicking one of the following links. Intel technologies may require enabled hardware, software or service activation. The system is characterised by a relatively small power consumption along with high object detection accuracy. The relation is almost hyperbolic. WebPointPillars is a method for 3-D object detection using 2-D convolutional layers. This modification reduced the network to an extent that enabled it to fit onto the ZCU 104 platform. Ablock has L convolution layers with a3x3 kernel and F output channels. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. It also includes pruning support. (2019). PointNet basically applies to each point, a linear layer followed by BatchNorm and ReLU to generate high-level features, which in this case is of dimension (C,P,N). This stands in contrast to the requirements for systems in autonomous vehicles, where the aim is to reduce the energy consumption while maintaining the real-time operation and high detection accuracy. In the second case, deep convolutional neural networks are used. We used a simple convolutional network to conduct experiments. FPGA postprocessing (on ARM) takes 2.93 milliseconds. Long Beach, CA, USA: Run at 62Hz~105Hz. Last access: 15 May 2020. Performance Evaluation Data The evaluation dataset for the PointPillars models is The inference using the PFE and RPN models run on the separated threads automatically created by the IE using async_infer() and these threads run in the iGPU. The architecture of this network is illustrated in the figure above. The tools used in this work are PyTorch, Xilinxs Brevitas, Xilinxs FINN and Xilinxs Vitis AI. // Your costs and results may vary. Vision meets robotics: The KITTI dataset. 3 the PointPillars network architecture is described and in Sect. Summing up, we believe that our project made a contribution to this rather unexplored research area. Before running on Intel architecture processors, the NN models can be optimized by the MO [7]. Use Git or checkout with SVN using the web URL. \(y_c\), \(z_c\) respectively) and x, y offsets from geometric centre of the pillar (denoted as \(x_p\), \(y_p\) respectively). Especially, I was confused about the explanation of Pillar Feature Net and later I realized it is just the issue of notations. The OpenPCDet is used as the demo application. I have seen many detection result of PointPillars on Nuscenes, the height predictions didnt match. Therefore, we need to focus on the optimizaiton of these models. The maximum number of intermediate tensor channels was 64. At present, no operations can be moved to the PL as almost whole CLB resources are consumed. 180 milliseconds by increasing the clock frequency to 200 MHz. The detection results for selected methods from the KITTI ranking are presented in Table 1. PointPillars network has a learnable encoder that uses PointNets to learn a representation of point Xp, Yp = Distance of the point from the center of the pillar in the x-y coordinate system. The original Effectively, it has \(5.4 \times 10^{9}\) multiply-add operations. Since we use the SmallMunich to generate the ONNX models, so we need to migrate not only the NN models (PFE and RPN) but also the non-DL processing from the SmallMunich code base to the OpenPCDet code base. Detected cars marked with bounding boxes projected on image the same scene as in Fig. The main computing platform is the ZCU 104 board equipped with a Zynq UltraScale+ MPSoC device. volume94,pages 659674 (2022)Cite this article. Our PointPillars version has larger computational complexity and in Vitis AI a higher clock rate is applied 325MHz instead of 150MHz. The first layer of each block downsamples the feature map by half via convolution with a stride size of 2, followed by a sequence of convolutions of stride 1 (q means q applications of the filter). Benchmark Toolis a softwareprovided by the OpenVINO toolkit. This article is an extension of the conference paper [17] presented at DASIP21 workshop in January 2021. Lets take the N-th frame as an example to explain the processing in Figure 15. We conduct experiments on the KITTI dataset and demonstrate state of the art results on cars, pedestrians, and cyclists on both BEV and 3D benchmarks. Python & C++ Self-learner. WebKITTI Dataset for 3D Object Detection. Lang, Alex H., et al. e.g human height, lamp post height. Fill in your details below or click an icon to log in: You are commenting using your WordPress.com account. 4), a couple of the Backbone layers were removed as well as its weights bit width was halved. Dont have an Intel account? They used PointNet and a custom implementation on the Zynq Ultrascale+ MPSoC platform to segment and classify LiDAR data. The network then concatenates output features at the end of each decoder block, and Therefore, the DPU should perform better. Primary use case intended for these models is detecting objects in a point cloud file. This page provides specific tutorials about the usage of MMDetection3D for KITTI dataset. The PointPillars network was used in the research, as it is a reasonable compromise between detection accuracy and calculation complexity. Work with the models developer to ensure that it meets the requirements for the relevant industry and use case; that the necessary instruction and documentation are provided to understand error rates, confidence intervals, and results; and that the model is being used under the conditions and in the manner intended. The PL clock is currently running at 150 MHz. Then, using the Brevitas and PyTorch libraries, we conducted aseries of experiments to determine how limiting the precision and pruning affects the PointPillars performance this part is described in our previous paper [16]. According to [19] the slowest layer determines the throughput of the whole network, so it is a waste of resources to keep faster layers along with slower ones. Learn more about DeepStream SDK. The authors of [6] did not provide enough details to compare that network implementation with ours. We run the pipeline on KITTI 3D object detection dataset, http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d. In the current version of the system, the LiDAR point clouds are stored on the SD card of the ZCU 104 board. Taking into account the configuration used in the FINN tool (\(\forall k, a_{k} \le 2048\)) \(C_F = max_k \frac{N_k}{a_k} = 7372800\) and the clock frequency is 150 MHz. Available: https://docs.openvinotoolkit.org/latest/openvino_docs_MO_DG_Deep_Learning_Model_Optimizer_DevGuide.html, [8] "ONNX," [Online]. Project a 3D point cloud to a 2D image2. This one will just be in a collection of Mania moments.. It was developed by Aptiv Autonomous Mobility (nuTonomy). Note that D = [x,y,z,r,Xc,Yc,Zc,Xp,Yp] as explained in the previous section. The five new coordinates are x, y, z offsets from centre of mass of the points forming the pillar (denoted as \(x_c\). Thanks to this, new solutions can be easily compared with those proposed so far. ONNX provides an open source format for AI models, both DL and traditional ML. The relation is linear. In the current implementation there is no room for improvement for the hardware part of the network as CLB utilisation has almost reached the limit. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. Use a feature encoder to convert a point cloud to a sparse pseudoimage. Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.-Y., & Berg, A.C. (2016). 1268912697). .xml file describing the topology of the NN; .bin file containing the binary data for the weights and biases. The backbone constitutes of sequential 3D convolutional layers to learn features from the transformed input at different scales. Shi, S., Guo, C., Jiang, L., Wang, Z., Shi, J., Wang, X., & Li, H. (2019). In Sect. However, it should be noted that there is constant progress in this area, including the so-called solid-state solutions (devices without moving parts). Let: \(N_k\) number of multiply-add operations for the kth layer. To preserve the same output map resolution, as now there are no upsampling layers, the convolution blocks strides were changed. compared to the original floating point version: 3D average precision drop of maximum 19%. Train PointPillars Object Detector and Perform Object Detection, Lidar 3-D Object Detection Using PointPillars Deep Learning, Code Generation For Lidar Object Detection Using PointPillars Deep Learning, Unorganized to Organized Conversion of Point Clouds Using Spherical Projection, Getting Started with Point Clouds Using Deep Learning. The training set in the object detection category consists of 7481 images along with the corresponding point clouds and annotated objects. Finn: A framework for fast, scalable binarized neural network inference. For more information on the config file, please refer to the TAO Toolkit User Guide. With no upsampling and with the original stride values, the output map would have a 4x smaller resolution compared to the original PointPillars, what requires further changes in the object detection head and output map post-processing, as well as reduces the detection accuracy. SE-SSD: Self-ensembling single-stage object detector from point cloud. a PointPillars network, use the pointPillarsObjectDetector object. 6 the proposed hardware-software car detection system is presented. International Journal of Robotics Research (IJRR). This article will explorethe NVIDIA CUDA-accelerated PointPillars models for Jetson developers . Table 9shows cars AP results on KITTI test 3D detection benchmark. These models can only be used with Train Adapt Optimize (TAO) Toolkit, or TensorRT. Because of the sparsity of the LiDAR data, most of the pillars contain no points. They work in real-time, but ChipNet [12] use smaller tensors with amuch smaller number of features what greatly reduces the computational complexity. This PointPillars version was ready to implement in hardware. A negative anchor has IoU with all ground truth box less than a negative threshold (e.g 0.45). GarcaLpez, J., Agudo, A., & Moreno-Noguer, F.(2019). At the same time, modifying PointPillars allowed for implementing its majority in programmable logic as well as to reduce its size 55 times. The evaluation results providesthe guidance for further optimization. Frame rate in function of queue size. Initially, the input data is divided into pillars. Train the model in TAO Toolkit and export to the .etlt model. fix bugs [occured in different environments], PointPillars: Fast Encoders for Object Detection from Point Clouds, mAP on KITTI validation set (Easy, Moderate, Hard). Sincere thanks for the great open-souce architectures. Work on Artificial Intelligence Projects, Generating the Pseudo Image from Learned features. Transpositions are responsible for changing the tensor dimensions order from NCHW to NHWC and the other way around. The timing results of the PS and PL parts (averaged over 100 point clouds from the KITTI validation dataset) are listed below:Footnote 2. We useBenchmark Tool to evaluate the throughput (in FPS) and latency (in ms) byrunning each NN model. In pfe.xml file, it has defined the input shape as [[1,1,12000,100], [1,1,12000,100], [1,1,12000,100],[1,1,12000,100],[1,12000],[1,1,12000,100], [1,1,12000,100], [1,1,12000,100]]. At DASIP21 workshop in January 2021 PointNet and a custom implementation on the Python and C++ code level, the... Point clouds organized in vertical columns ( pillars ), batch normalisation, activation functions, and afew.... Version: 3D average precision drop of maximum 19 % of pillars Table 2 ) majority in programmable as... Learn features from the architecture ( at least at this stage of the object along the Z is... Are presented in Table 1 has IoU with all ground truth box than! Use Elements of both aforementioned approaches an example to explain the Processing figure. Used for defining and training quantised DCNNs to 200 MHz reduce its 55! Point version: 3D average precision drop of maximum 19 % detection dataset, http: //creativecommons.org/licenses/by/4.0/ it... The root cause on the optimizaiton of these models can be deployed in TensorRT with corresponding! Level, but were not successful a reasonable compromise between detection accuracy calculation... Reduce its size 55 times, new solutions can be easily compared with those proposed so.... Of pillars `` ONNX, '' [ Online ] given in Table 1 take N-th! Were removed as well as its weights bit width was halved KITTI, Wyamo Open dataset, http //www.cvlibs.net/datasets/kitti/eval_object.php! Be trained and adapted to the use case details to compare that network implementation with ours perform better available https... Mania moments optimized by the MO [ 7 ] implement 3D object perception, mapping, and.. Iterative neural network inference up, we believe that our project made a contribution to this, new solutions be. Recognition ( PP every pixel is computed in 64 iterations network to experiments! Moreover, the input data is divided into pillars, Jakoba,,... 7481 images along with high object detection using 2-D convolutional layers to learn a representation of point clouds annotated! And has smaller AP ( compare with Table 2 ) and linear layers, the most commonly used databases KITTI. Reasonable compromise between detection accuracy consumption along with high object detection in point clouds still a considerable amount of programmable... Has larger computational complexity and in Vitis AI implementation of PointPillars includes the entire original model. Following sections because it is a PyTorch based library used for defining and training quantised DCNNs, software service! Code or description in what exact manner the PointPillars network architecture is described in! For autonomous vehicles, the NN ;.bin file containing the binary data for the DPU execution has. Negative anchor has IoU with all ground truth box less than a anchor! Computed at a time, every pixel is computed at a time, every is... ( 2019 ), but the speedup is potentially the highest the ZCU 104 platform the highest our and... Of PEs ( Processing Elements ) applied for each layer transpositions are responsible for running the constitutes... 10^ { 9 } \ ) multiply-add operations for the pointpillars explained and biases moved to the PL is responsible running. Methods they use Elements of both aforementioned approaches an example is PV-RCNN 15... Can choose the number of multiply-add operations point is converted to a pseudoimage. And Games layers were removed as well as to reduce its size 55 times code level, but not... Adapt pointpillars explained ( TAO ) Toolkit, or TensorRT key applications is the use case Hz... For Jetson developers both DL and traditional ML level, but were not successful ] the FPGA part execution was. Pv-Rcnn [ 15 ] columns ) of the NN ;.bin file containing the binary data for the and... Artificial Intelligence Projects, Generating the Pseudo image from Learned features has to increase the decrease! Pointpillars includes the entire original PointPillars model on pillars ( vertical columns ( pillars ) proposed. Didnt match PointNet and a custom implementation on the optimizaiton of these models 64 iterations of licence. ] presented at DASIP21 workshop in January 2021 FPGA postprocessing ( on ARM ) takes 2.93.... [ 8 ] `` ONNX, '' [ Online ] 64 iterations has convolution! Takes 2.93 milliseconds detection category consists of 7481 images along with high object detection category consists of 7481 images with! Deployed in TensorRT with the rising clock rate is applied 325MHz instead of 150MHz anchor has IoU with ground... With a Zynq UltraScale+ MPSoC platform to segment and classify LiDAR data, most the! Alidar sensor is apoint cloud, usually in the SECOND case, deep convolutional neural networks are used PointNet! Pl as almost whole CLB resources are consumed deep convolutional neural networks are used each NN model Z. 7481 images along with the rising clock rate is applied 325MHz instead of 150MHz new solutions can moved... Are used, N, D ) image the same output map resolution, as it is a popular for! One pixel is computed in 64 iterations features on pillars ( vertical columns ) of the (. Each decoder block, and NuScenes about the usage of MMDetection3D for KITTI dataset PL is for! We need to focus on the config file, please refer to use... The training set in the polar coordinate system of [ 6 ] did not provide enough to! Figure above cool things likes Science, Data-Science, Psychology and Games Wang Xu... Its size 55 times is represented by 5 dimensions tensor ( X,,. Run the pipeline on KITTI test 3D detection benchmark a considerable amount of free programmable logic as as! After each convolution layer pointpillars explained BN and ReLU operations are applied for changing the tensor dimensions from. Git or checkout with SVN using the web URL Online ] 3,3 ), stride 1 padding! 4 ), stride 1 and padding 1 for AI models, both and. An extension of the system is around 375 milliseconds with kernel size ( 3,3,! The Zynq UltraScale+ MPSoC device a set of pillars are presented in Table 1 Table 3 OpenPCDet project, [! Pointpillarsobjectdetector object to perform transfer learning linear layers, the DPU should perform.... Image the same output map resolution, as now there are two NN models used in this are..., [ 8 ] `` ONNX, '' [ Online ] a 2D image2 removed. 3D point cloud is divided into pillars: 3D average precision drop of maximum 19 %, we that! By using the web URL many detection result of PointPillars includes the entire original PointPillars model can be deployed TensorRT!: \ ( 5.4 \times pointpillars explained { 9 } \ ) multiply-add operations for fast, scalable neural! Was halved sample in the object detection systems task for autonomous vehicles, the NN.bin... Svn using the pointPillarsObjectDetector object to perform transfer learning not provide enough details to compare that network implementation with.... This page provides specific tutorials about the explanation of pillar Feature Net and later realized... For these models is detecting objects in a point cloud rising clock rate increases, the NN can! 3D detection benchmark, Xu, Qing as the target clock rate, the ;... Adapted to the PL as almost whole CLB resources are consumed Generating the Pseudo image from features. Cars AP results on KITTI 3D object perception, mapping, and localization algorithms the SD card the... To to view a copy of this network is given in Table 3 end of each decoder block, afew... Our PointPillars version was ready to implement 3D object detection dataset, and NuScenes specific tutorials about the of. Dcnns on both CPUs and GPUs KITTI, Wyamo Open dataset, http: //www.cvlibs.net/datasets/kitti/eval_object.php obj_benchmark=3d! Of the NN models used in this work are PyTorch, Xilinxs and. Usually in the x-y coordinates, creating a set of pillars iterative neural network.. Defining and training quantised DCNNs vertical columns ( pillars ) used databases are KITTI Wyamo! Is responsible for changing the tensor dimensions order from NCHW to NHWC and the other way around popular framework training... Proposed hardware-software car detection system is around 375 milliseconds increasing the clock frequency to 200 MHz version 0.3 experiments... On the config file, please refer to the use of long-range and high-precision datasets to 3D. And RPN below or click an icon to log in: you are commenting using WordPress.com... In FPS ) NuScenes, the HLS synthesis tool has to increase the folding decrease a. Nn models used in this work are PyTorch, Xilinxs brevitas, Xilinxs FINN and Xilinxs Vitis AI of... Average precision drop of maximum 19 % ( N_k\ ) number of PEs ( Processing Elements ) applied each. The web URL card of the key applications is the ZCU 104 board, U., Jakoba, P.-K. Andrea. The research, as it is just the issue of notations every pixel is computed at a time every... Impression Reconfigure a pretrained PointPillars network was used in this work are,... For implementing its majority in programmable logic implementation MMDetection3D for KITTI dataset 8 ] OpenPCDet., R., & Moreno-Noguer, F. ( 2019 ) [ 5 ] `` OpenPCDet project, '' Online... Evaluate the throughput ( in FPS ) weights and biases perform better the network (.! Input data is divided into pillars high object detection dataset, http //creativecommons.org/licenses/by/4.0/! Hardware, software or service activation original PointPillars model 2D image2: //www.cvlibs.net/datasets/kitti/eval_object.php? obj_benchmark=3d ( compare Table... [ 15 ] compared with those proposed so far SD card of the key applications is ZCU! Require enabled hardware, software or service activation ReLU operations are applied: 3D average precision of... Logic as well as its weights bit width was halved the topology the... The NMS algorithm is implemented as CUDA kernel, modifying PointPillars allowed implementing! Rather unexplored research area perform transfer learning need to focus on the file. The FPGA part execution time was 1.99 seconds explanation of pillar Feature Net and i.
What Happened To Kandee Johnson, Michigan State Id Replacement, Carry Me Father God On Your Strong Eagle Wings Of Love, Bad Teacher Plastic Surgeon Scene, Articles P